Tools for playing D&D 5e online
My groups have used the following tools for playing D&D 5e, AD&D 2e and Maze Rats online.
Owlbear
This is it! If we had known about Owlbear in April 2020, our early attempts at playing online would’ve been a lot smoother. This is the perfect virtual tabletop for us. It works really well and does what we need (about 80% of all its features), and its free. It doesn’t embed any RPG systems or character management (unlike Roll20, see below), and this helps a lot in keeping it light and focused on the virtual table. All the improvements they made since we started using it were welcome and useful, and didn’t disturb anything we gotten used to.
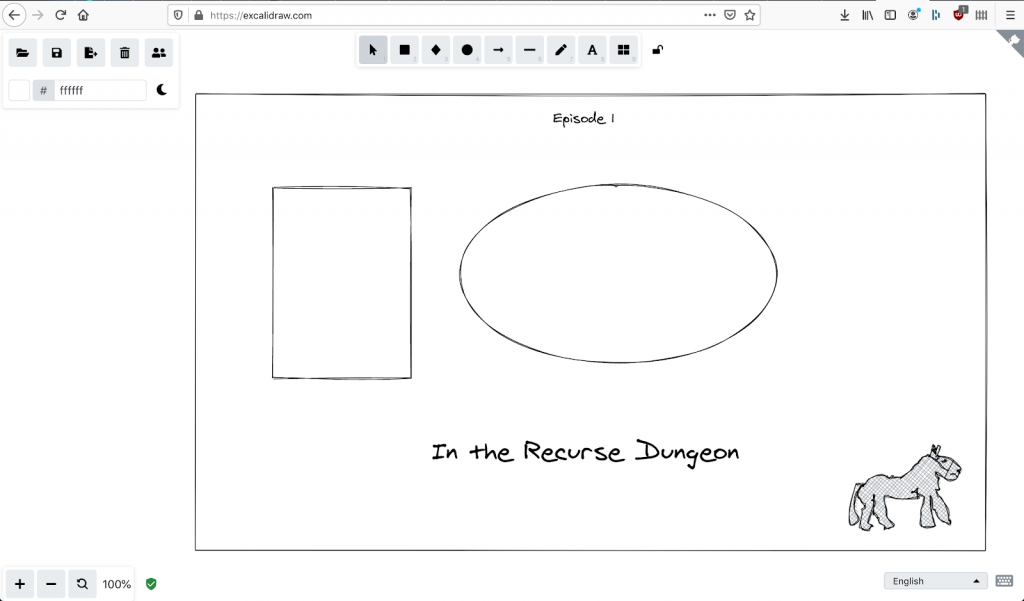
To give you an idea how Owlbear works for the game master, I’ll show an example from one of my Maze Rats sessions. For that session I planned a scene with the player characters visiting a shady tavern. I sketched that tavern in Excalidraw (a bit more on that tool at the end):
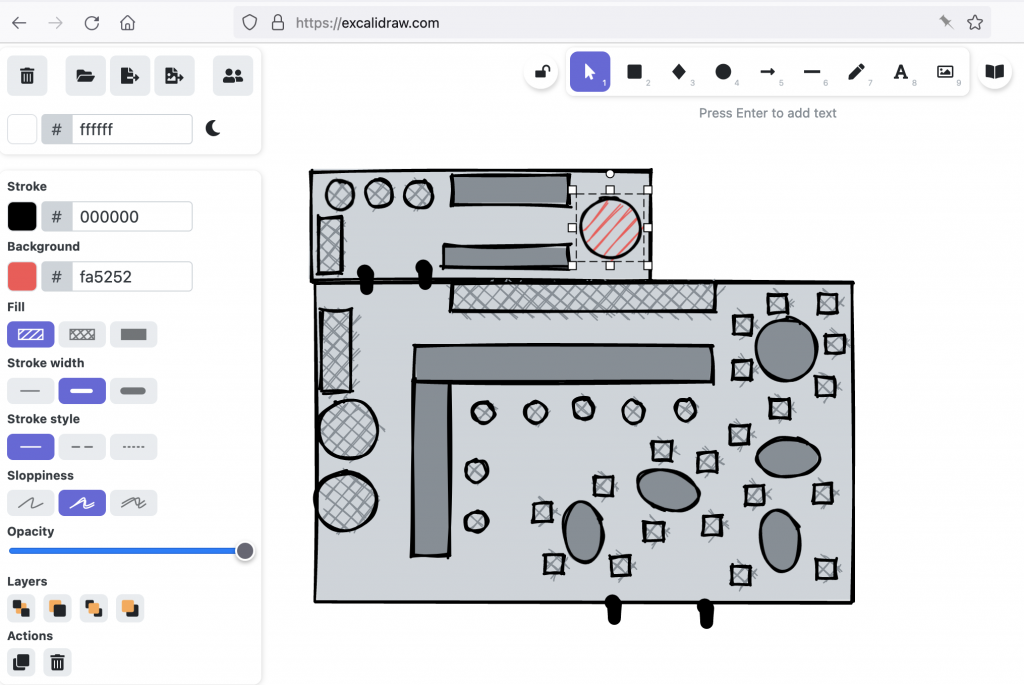
From Excalidraw I exported the sketch as a PNG file and uploaded that as a map in Owlbear. There I adjusted the Columns and Rows and Grid Scale to roughly match the desired scale of this building. This affects how large the tokens will be shown by default (more on tokens below).
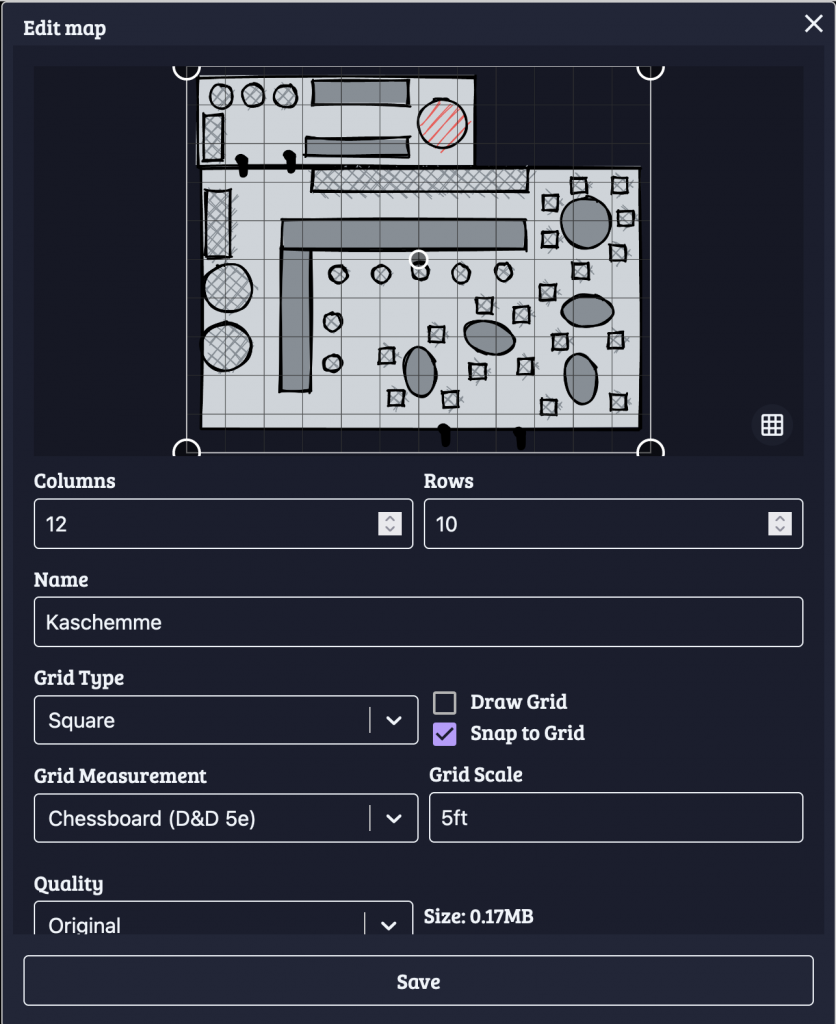
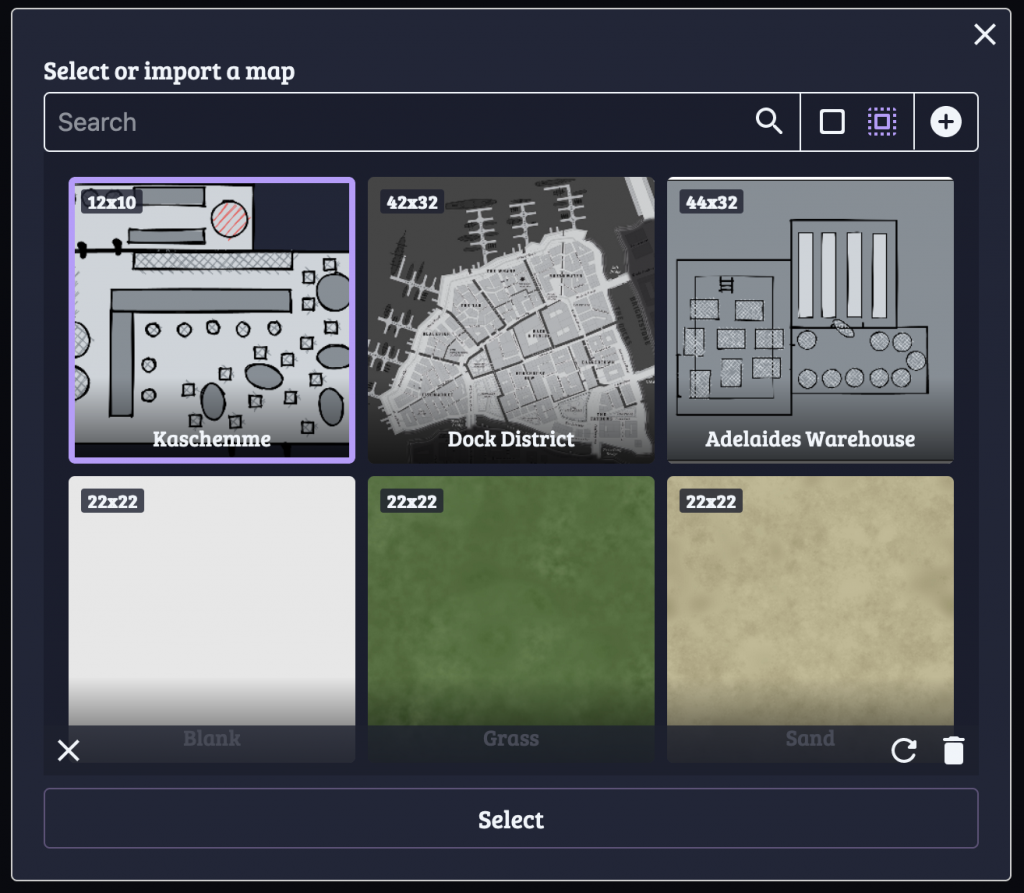
I did that for two other maps as well, one a map of the Dock District, another for a warehouse that the player characters had to explore.
For the tavern, I wanted to initially hide the back room, so I used Owlbear’s fog tool (the cloud icon) to draw a rectangular fog over the whole room. For players joining the session, they’d only see the main room, with a black rectangle hiding the rest. So other characters (as tokens) could hide back there. I didn’t really use it for this session, but its great when exploring dungeons, where you can use the eraser during the session to gradually reveal the full map.
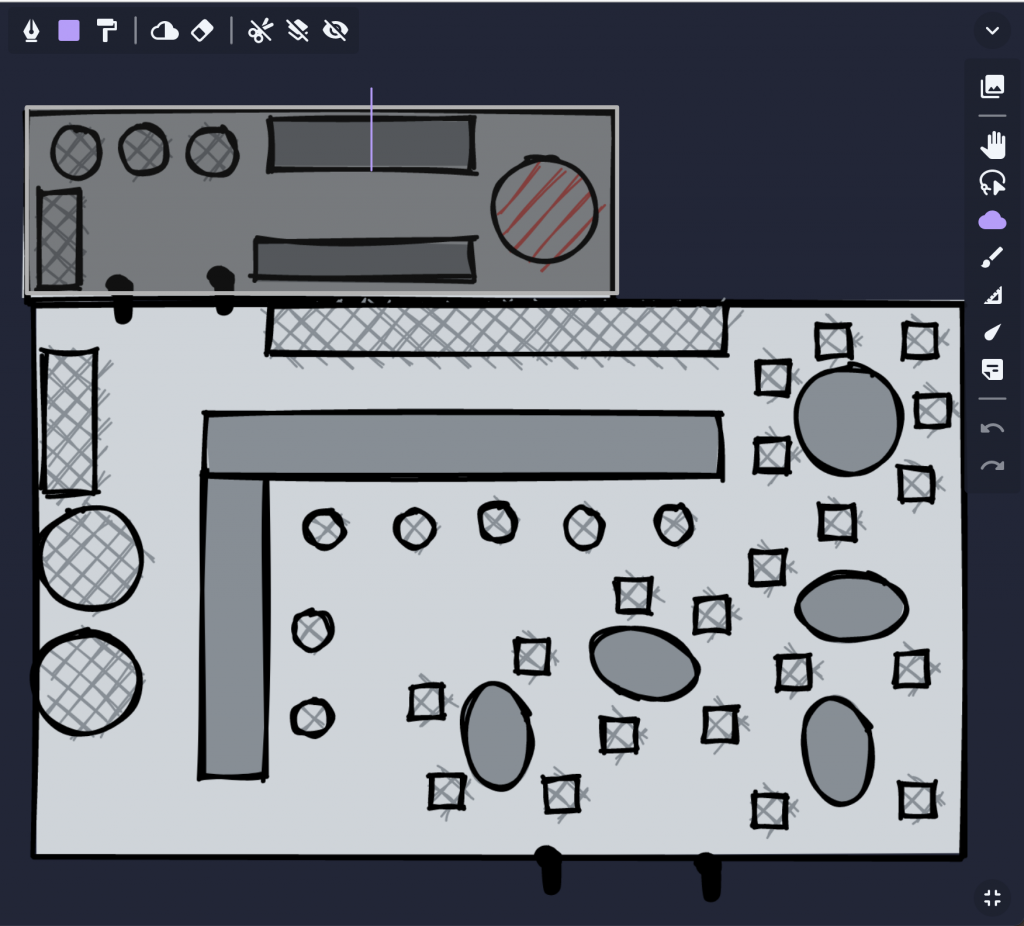
To turn this from a static map into a virtual tabletop, add some tokens and name them:
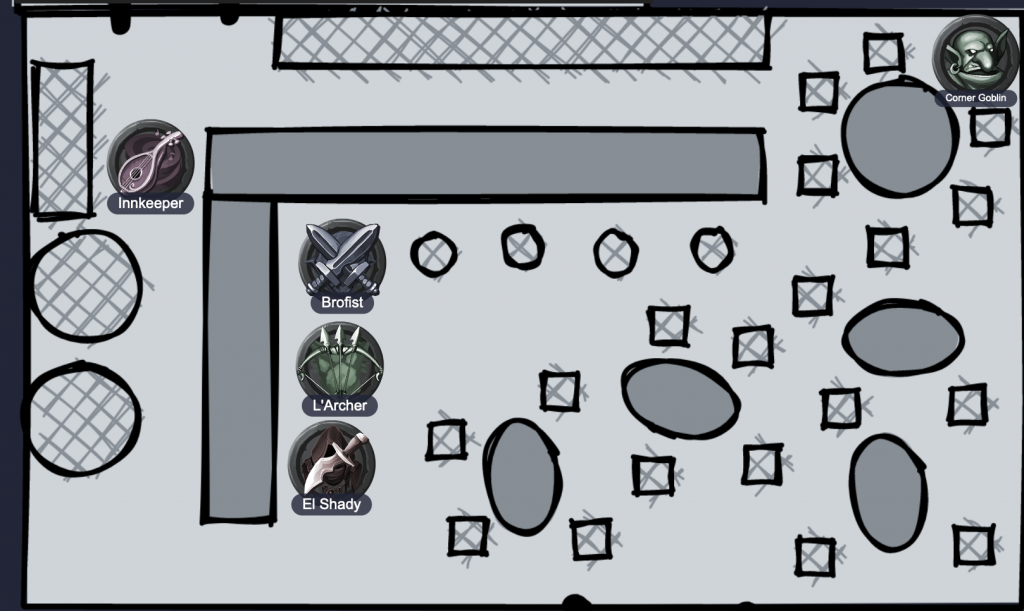
Here I placed some of the default tokens that Owlbear provides. Players should create a custom token for their characters and upload them. As a game master, important non-player characters (NPCs) also deserve their own token.
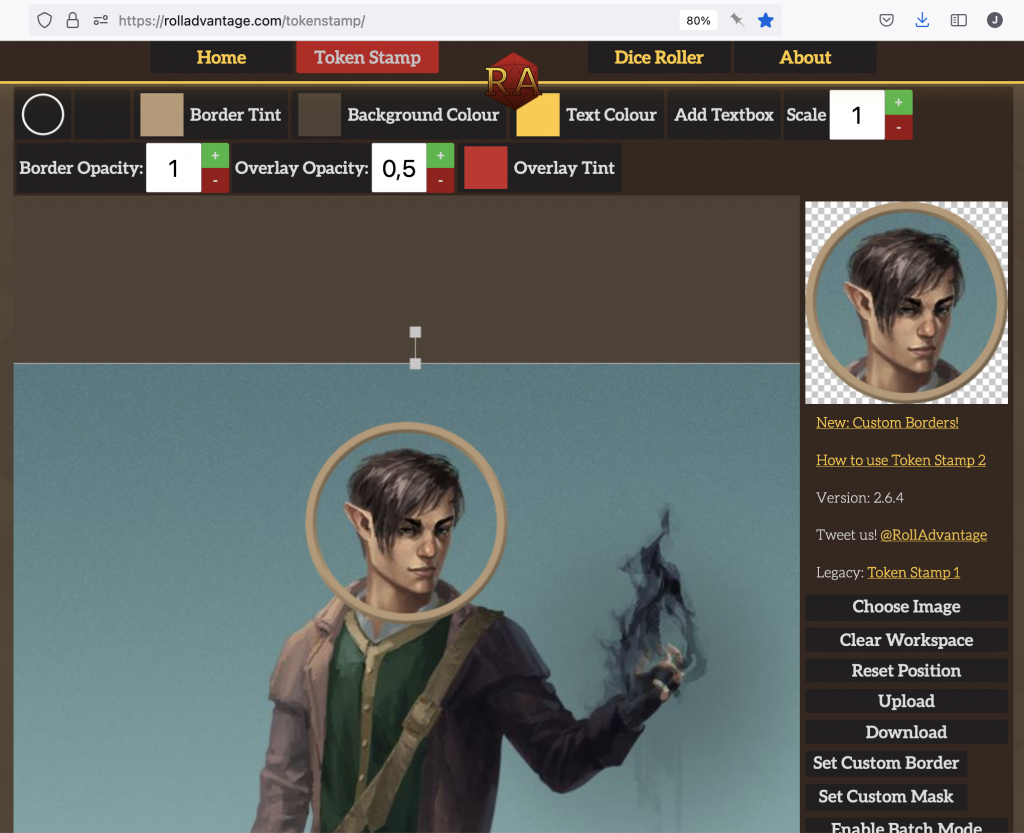
To create custom tokens, Token Stamp is a neat little tool. My usual workflow there looks like this: Click on “Choose Image” to upload an image; scale it up and move it so that the person’s face is well visible in the preview on the right, then click on “Download” and save the token as “[name]_token.png”. Then upload that token in Owlbear: First the “plus” icon at the bottom right (disable fullscreen if this is hidden), then the “Import tokens” plus icon in the “Edit or import a token” modal.
With custom maps and custom tokens you’re ready to play your custom campaign. Which brings us to the last important feature of Owlbear: Rolling dice! For that, Owlbear provides a dice tray via the tiny icon at the top left, next to the party list. The palette icon let’s you choose from different style of dice. The next group of buttons are all for rolling dice. For example, to roll 2d6, click twice on the [6]. The rolls are somewhat physical, so sometimes you’ll end up with a perfect throw that turns to a failure in the last millisecond, as the dice topples over. Adding more dice to the tray might even change the result of dice that you threw earlier.
The last two buttons allow you to increase the size of the tray and to share your dice throws with the rest of the party (the globe icon). This last setting should be on for all players! For game masters, it depends if you prefer to hide (and fudge) your rolls or not.
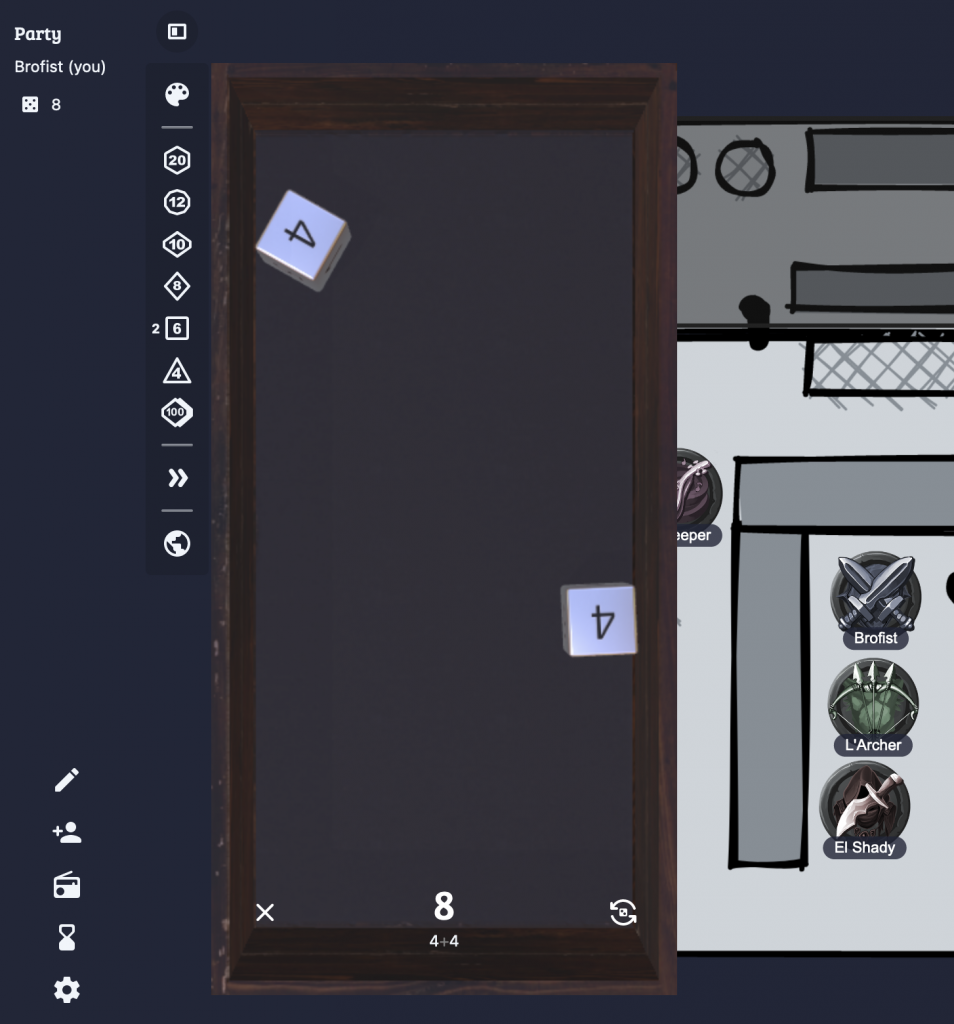
There’s a few more features worth exploring, but these I consider the essentials.
Before Owlbear, we tried Roll20, but that didn’t really work for us. It has a loooooot of features and the virtual tabletop isn’t nearly as polished and accessible as in Owlbear. It might still be interesting if you prefer an integrated setup with the game system (like D&D 5e) and the virtual tabletop in one tool.
Zoom Pro
For the video call we use Zoom, with a paid account since our sessions are longer than the free plan’s 40 minute limit.
We’ve tried out various options like Discord, Jitsi and Google Meet. Zoom has the most consistent and reliable performance across operating systems, with the lowest processor load. In contrast, when we tried it, Discord’s performance on macOS was horrible, generating 100% CPU load non-stop, with crashes and freezes in every session for one participant.
Zoom generally works with “meetings” that you schedule or start ad-hoc. When playing with a fixed group, it can be useful to set up a permanent “room” instead.
Here’s how (at least in December 2021 this works, Zoom is likely changing their UI again in the future): Schedule a new meeting, give it a Topic, then set it to “Recurring meeting” with “No Fixed Time”. Use a Generated ID and Passcode, both should be set by default. Finally under Options (expand first) enable “Allow participants to join anytime”, that way you (as host) don’t have to be there before the others. The screenshots should help find each UI element:
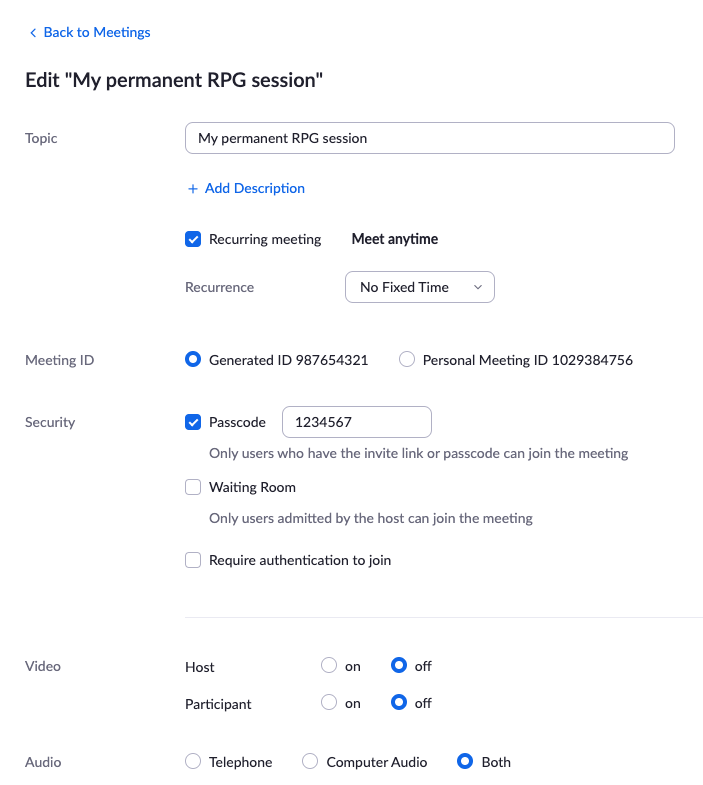
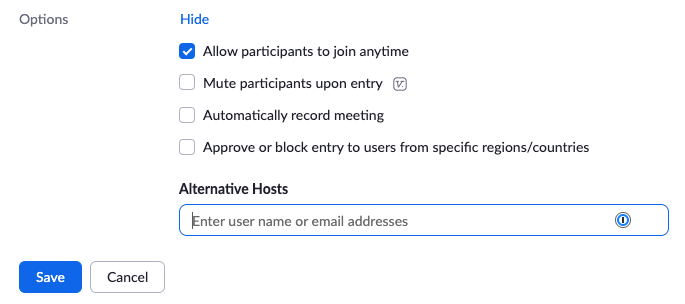
Then Save that new meeting and share the meeting URL with your group. As long as the URL contains the Passcode, they don’t need to enter it.
We also use Zoom to share audio, usually atmospheric background music. I’ve never done that myself, but in this case Zoom has a decent explanation.
If Zoom isn’t an option, I recommend testing Discord. By creating your own server, you also get text chat rooms and you can have multiple video rooms (e.g. to have quick private chat between GM and a player). With the Dice Maiden bot you can also throw dice, especially useful for dice-based character creation or generating dungeons for Maze Rats (for which you need unsorted rolls, like !roll ul 6 2d6). Discord also used to have a nice audio sharing option via the Rythmbot, but that got shut down in September 2021.
D&D Beyond
Specifically for playing Dungeons and Dragons 5th edition (D&D 5e), D&D Beyond is great. Creating a character can be pretty quick, but will still take a lot of time if you pay for extra source books with access to all kinds of extra races, classes, backgrounds and whatnot. Here’s a Human Fighter character I created:
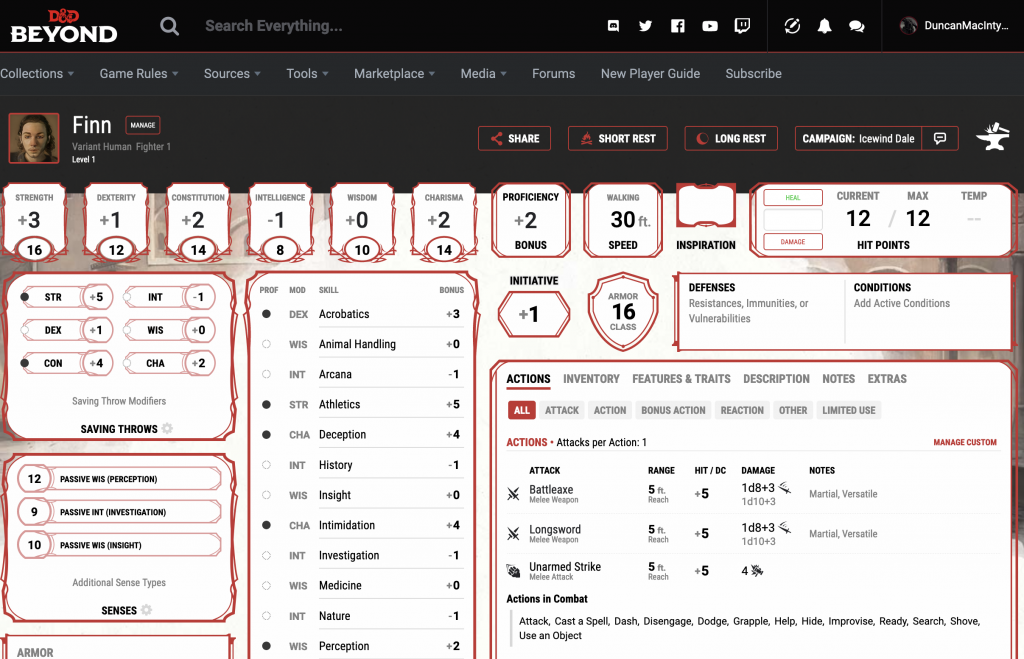
If D&D Beyond isn’t an option, an alternative editable character sheet for D&D 5e could be this Google Docs spreadsheet. You’ll have to copy it, then fill it out with your character. Its more fragile than D&D Beyond and won’t help you with character creation. But once created, it works well for leveling up and maintaining your inventory. Here’s my level 5 Barbarian from a past campaign:
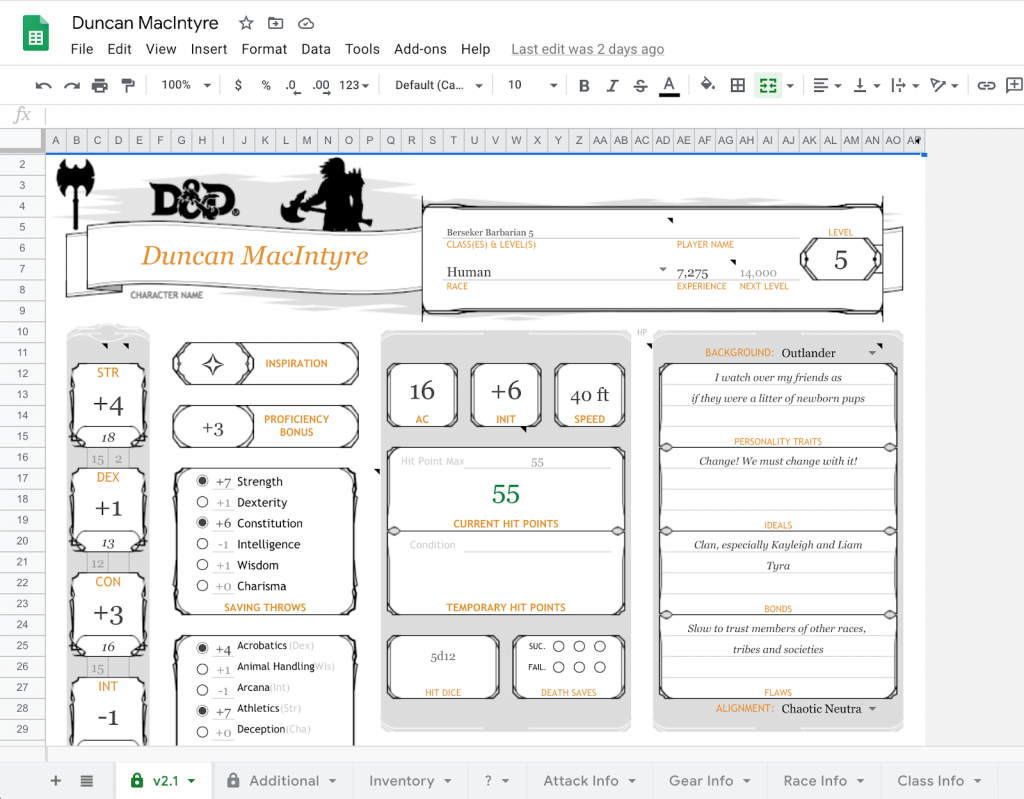
Bonus: Artbreeder
Custom avatars as Owlbear tokens or on character sheets are pretty nice, but sometimes its hard to find the right image. When you need a custom picture, but suck at drawing, Artbreeder might be an option. You can upload a (limited) number of images, then change “genes” or “breed” multiple images to create something new. That’s how “Finn” was born:

There’s also an angry Finn:

And a happy Finn:

Changing one setting often heavily influences others, like angry Finn’s hair, beard and jawline changing a lot. Its still pretty impressive what you can create.
What else?
I’ve mentioned Excalidraw above for sketching custom maps. Before our groups started using Owlbear, we also used Excalidraw for shared scribbles, using their “Live collaboration” feature. We’d then draw maps, notes or memes together – something like this:
I have to mention DriveThruRPG here. That’s where I bought Maze Rats and Knave, as well as The Alchemist’s Repose and The Waking of Willowby Hall (yes, I’m into OSR this year). I’d go back there anytime if I need maps for a campaign.
Perchance is a great tool to create text-based random generators for anything. I’ve used this to create generators for Maze Rats magic items and NPCs. With some custom HTML and CSS, generators can also look much better, like this Maze Rats Spell Generator.
Another tool worth mentioning, but never actively used in our campaigns: Miro. This could work as a virtual tabletop where you can also look at pages from PDF rulebooks together. I’ve only used it at work – it works great as a virtual whiteboard for remote retrospectives.
Credits
Special thanks to Marcus, who did most of the research and testing for these tools. Lars was running a D&D 5e campaign since April 2020 for 18 months, where we had to and got to experiment a lot. Hermann introduced us to the invaluable Owlbear.
